In October this year, I took part in the Huawei Honorcup Marathon 2 conducted by Codeforces, with a first prize of USD$10,000 at stake, and managed to place 59th out of 236 submissions globally.
I didn't win the USD$10,000, nor any Huawei devices or a job. But I did get a signed certificate of participation and a hoodie shipped to me from Moscow:


The task
The announcement described the task as “challenging … without [an] exact solution”, which caught my eye and was the reason I decided to take part—I was quite disillusioned with usual competitive programming contests which had a single correct solution.
It turned out to involve reassembling scrambled square-piece jigsaw puzzles. For example, here's a scrambled image and the original from the training data provided:


Some literature review
It's easy to say that this is a perfect problem to tackle with machine learning and artificial intelligence, but I wanted to start with something simpler. A bit of cursory research turned up some news about an algorithm that beat a jigsaw-solving record, which led me to the corresponding research paper (project page) by Andrew Gallagher.
The paper in question did point in the right direction for tackling the contest task, but it was also slightly excessive—the algorithm described was capable of solving multiple square-piece jigsaw puzzles mixed together and with pieces in any orientation, while the contest problem only required solving a single puzzle at a time and without any piece rotation.
Looking through the references in the paper, I came across an earlier paper (project page) by a team from the interdisciplinary Computational Vision Laboratory which focused on the latter case, also known as a Type 1 square-piece jigsaw puzzle. It seemed to fit the contest task exactly.
Implementing the solver
The approach described by Pomeranz et al. was much simpler than Gallagher's, and the authors even published the code they used. Fortunately, I did not have to contend with the ethical considerations of submitting a solution entirely based on someone else's work—it was written in MATLAB, which I did not own a license for (I did try asking my company's software licensing team, who informed me that it cost USD$2,150 per-seat as of 2017).
I ended up reimplementing the algorithm from the paper in Python with NumPy, albeit not in a clean-room environment since I was able to reference the original MATLAB code when in doubt. This was my first successful attempt at implementing a research paper and I learnt a lot from the process.
After the contest ended, I published my implementation on GitHub:
yi-jiayu/shuffled-imagesA fully-automated greedy square jigsaw puzzle solver based on the paper of the same name by Pomeranz et al.https://github.com/yi-jiayu/shuffled-images
Generating the solutions
Besides implementing the algorithm, another challenge was actually running it on the dataset provided. The contest was split into three problems, each with a different puzzle size: 8 by 8, 16 by 16 and 32 by 32, each size having an exponentially larger number of possible combinations than the last and made even harder by a smaller edge length to use to match pieces. The dataset included 600 test images (with solutions provided), and 300 images each in the validation and test sets for each size, a total of 3600 images in all.
While I was able to solve the 8 by 8 puzzles on my own laptop, I had trouble doing so for the larger puzzle sizes due to a limited amount of compute time and the need to use my machine for other tasks (I couldn't even compile a single codebase while trying to solve the 16 by 16 puzzles in the background while at my day job).
Luckily, this was a hurdle that could be overcome by simply throwing even more compute (and money 💸) at it—I spun up two DigitalOcean 16 vCPU CPU-optimised droplets (USD$320/mo) and put all their cores to work using GNU Parallel:
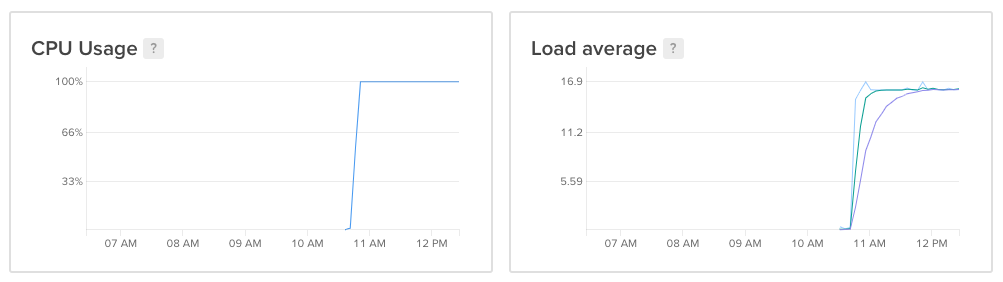
A single machine took about 20 hours to solve 300 32 by 32 puzzles (compared to just under an hour for 300 16 by 16 puzzles). With this setup, I was able to finish generating my solutions for all three size categories in time for the contest deadline with a total spend of around SGD$50.
Final thoughts
One of my regrets was not being able to add any of my own input in addition to what was described in the paper in my final solution—I wasn't able to contribute anything novel other than my implementation work. Even one of my big gains towards the end of the contest when I realised I could run the solver multiple times with random initial states and take the best result came from rereading the paper and noticing something the authors had already pointed out that I missed.
Nevertheless, I had fun taking part in this contest and came away with something to show for it as well as learning a lot, so I guess it was time (and money) well spent.