Recently, I downloaded some data from the FPL website and ingested it into a SQLite database so it could be queried and explored with SQL and potentially exported to other formats such as CSV afterwards.
Here are some things you can do with it:
An example query selecting the top point scorer from each team:
select
p.web_name,
t.name as club,
r.singular_name_short as position,
max(p.total_points) as total_points
from players p left join teams t on p.team = t.id
left join roles r on p.element_type = r.id
group by p.team;
| web_name | club | position | total_points | cost |
|---|---|---|---|---|
| Salah | Liverpool | MID | 303 | 10.6 |
| Sterling | Man City | MID | 229 | 9.1 |
| Kane | Spurs | FWD | 217 | 13.1 |
| Mahrez | Leicester | MID | 195 | 8.7 |
| Azpilicueta | Chelsea | DEF | 175 | 6.9 |
| De Gea | Man Utd | GKP | 172 | 5.9 |
| Groß | Brighton | MID | 164 | 5.9 |
| Fabianski | Swansea | GKP | 157 | 4.7 |
| Shaqiri | Stoke | MID | 155 | 6.1 |
| Pope | Burnley | GKP | 152 | 5 |
| Pickford | Everton | GKP | 145 | 4.9 |
| Milivojevic | Crystal Palace | MID | 144 | 5.2 |
| Arnautovic | West Ham | MID | 144 | 7.1 |
| Lacazette | Arsenal | FWD | 138 | 10.3 |
| Doucouré | Watford | MID | 136 | 5.2 |
| Lössl | Huddersfield | GKP | 135 | 4.6 |
| Pérez | Newcastle | FWD | 124 | 5.5 |
| Foster | West Brom | GKP | 123 | 4.3 |
| Tadic | Southampton | MID | 122 | 6.2 |
| Begovic | Bournemouth | GKP | 112 | 4.5 |
Check out some more sample queries and results.
You can download the SQLite database file here or from GitHub together with the code used to create it:
yi-jiayu/FPLFPL - Fantasy Football League analyticshttps://github.com/yi-jiayu/FPL
Motivation
I've been working on figuring out the optimal set-and-forget team (Some examples of set-and-forget teams: here, here and here) ex post for the most recent season of Fantasy Football League by formulating the problem as an integer linear optimisation problem, but due to a handful of setbacks I don't have an answer yet.
One of these setbacks was when, after taking 9 hours to solve my model in OR-Tools, I found out that the data I used—and hence the solution I arrived at—was wrong!
I had been using the CSV data dumps for each gameweek from Fantasy Overlord, but upon closer inspection, I noticed some issues with the data.
- The data for gameweek 37 was the same as the data for gameweek 38—the data for gameweek 38 had been repeated and the actual data for gameweek 37 was missing.
- I needed a weekly count of minutes played by player, but the data contained a cumulative count of minutes played since gameweek 1, so I had to calculate it myself for each week by taking the difference from the previous week.
- The values for minutes played played in gameweek 0 were not 0 but instead the total minutes played by each player in the previous season, so my calculated minutes played for gameweek were wrong.
This spurred me to put together a dataset myself, in a reproducible way and from an authoritative source of data—the FPL website itself.
Building the dataset
The FPL website
Fantasy Premier League, Official Fantasy Football Game of the Premier LeagueOfficial Fantasy Premier League 2017/18. Free to play fantasy football game, set up your fantasy football team at the Official Premier League site.https://fantasy.premierleague.com/
The Fantasy Premier League website is an excellent example of decoupling dynamic data from static page content because of the way it fetches data asynchronously from separate endpoints, compared to traditional server-rendered pages where everything is combined in the server response (although both approaches have their own advantages).
This makes it extremely friendly to external applications due to the data API serving up easy-to-consume JSON responses. Here are some of the XHR requests made by the website featuring a request for a specific player's information:
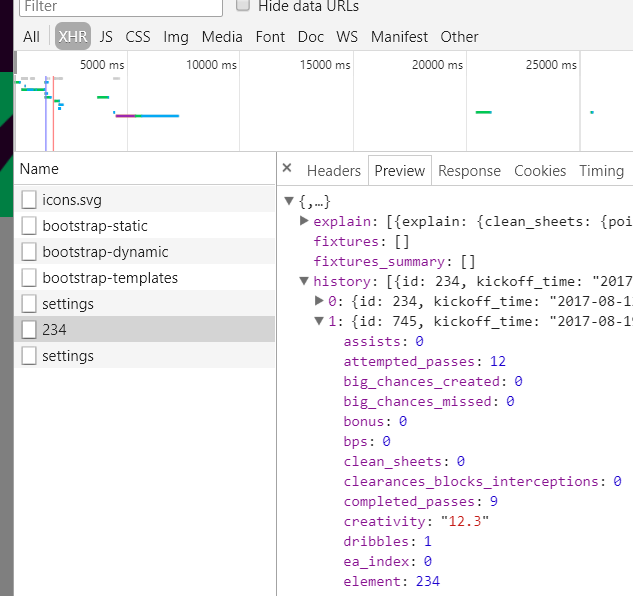
The dataset uses data from the following endpoints:
https://fantasy.premierleague.com/drf/bootstrap-static—This is a collection of multiple types of data which, based on the name, is probably to bootstrap the web interface. It contains things like headings, game settings (how points are awarded, how much transfers cost), information for each gameweek (deadlines, average and highest points), and details for each team and every single player.https://fantasy.premierleague.com/drf/fixtures—This contains details on every match over the entire season such as the time, teams playing, final score and the points awarded to the participating players, as seen beneath your team on the “Points” tab: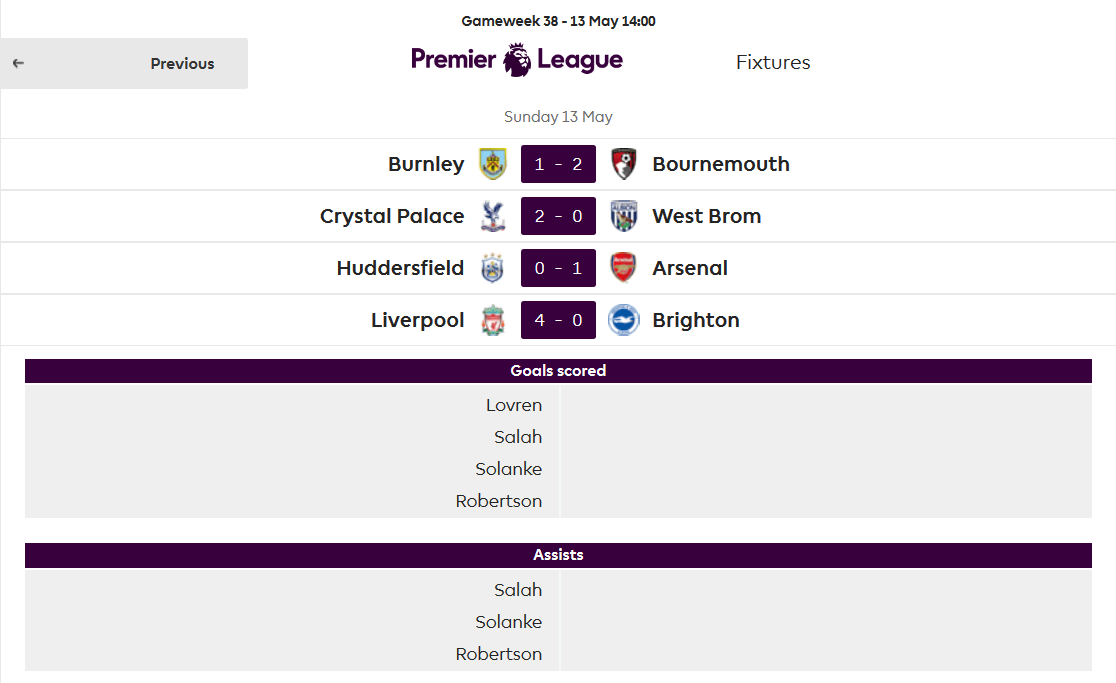
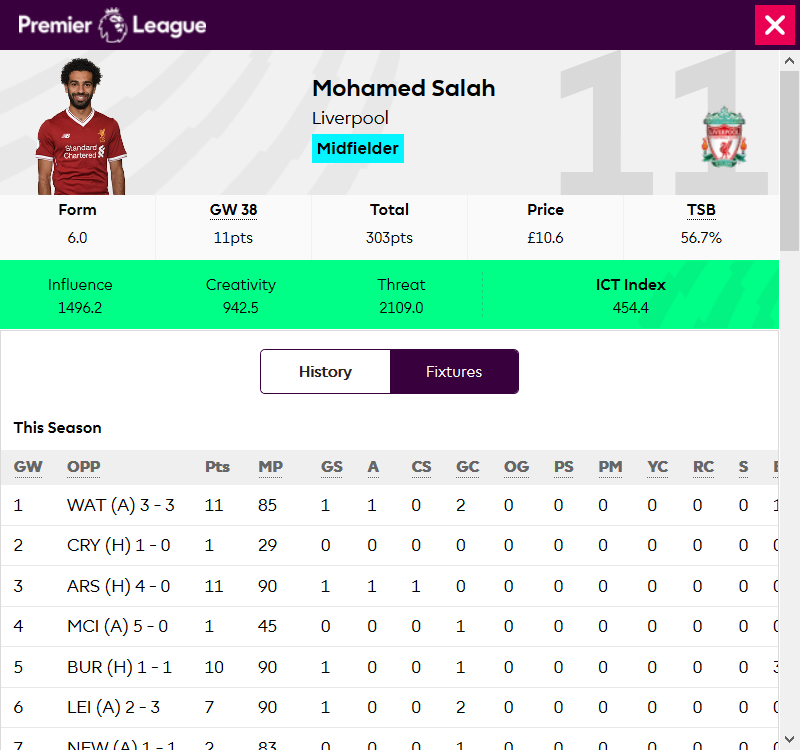
https://fantasy.premierleague.com/drf/element-summary/{element_id}—This is a separate endpoint for each player (players are referred to aselements) and returns the player's performance in every match in the current season as well as per-season summaries for previous seasons, visible in the player information dialog: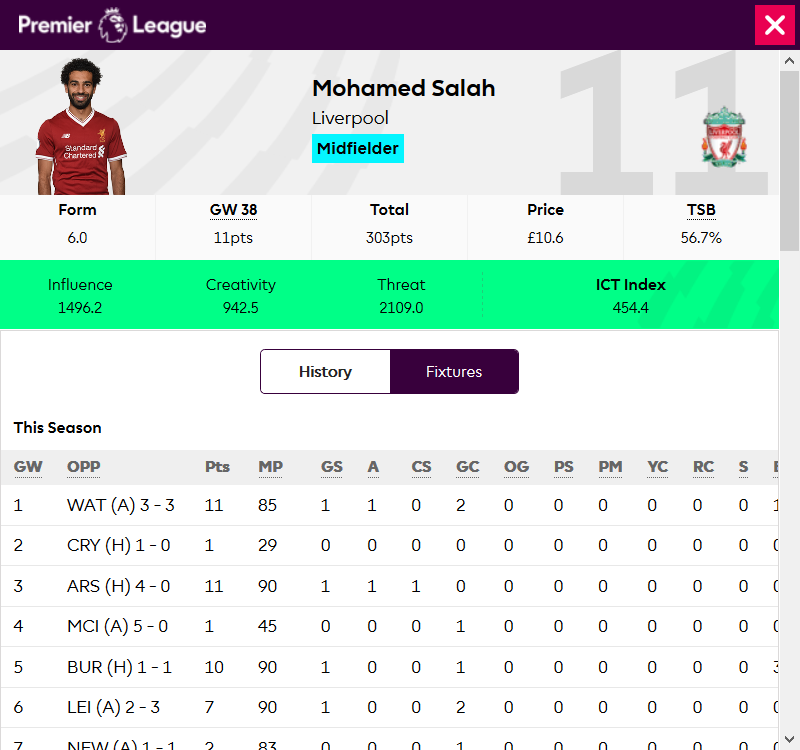
Unlike a similar API used by its parent Premier League website served from https://footballapi.pulselive.com/ which requires requests to include an Origin: https://www.premierleague.com header, the data API used by the FPL website can be accessed directly through your browser.
Populating the database
The objects returned by the FPL API are quite comprehensive, with some of them—especially those related to players—having more than 50 different attributes. This is a sample player object:
{
"id": 234,
"photo": "118748.jpg",
"web_name": "Salah",
"team_code": 14,
"status": "a",
"code": 118748,
"first_name": "Mohamed",
"second_name": "Salah",
"squad_number": 11,
"news": "",
"now_cost": 106,
"news_added": "2018-04-04T20:31:18Z",
"chance_of_playing_this_round": 100,
"chance_of_playing_next_round": 100,
"value_form": "0.5",
"value_season": "28.6",
"cost_change_start": 16,
"cost_change_event": 0,
"cost_change_start_fall": -16,
"cost_change_event_fall": 0,
"in_dreamteam": true,
"dreamteam_count": 11,
"selected_by_percent": "56.7",
"form": "5.0",
"transfers_out": 2661454,
"transfers_in": 4223518,
"transfers_out_event": 0,
"transfers_in_event": 0,
"loans_in": 0,
"loans_out": 0,
"loaned_in": 0,
"loaned_out": 0,
"total_points": 303,
"event_points": 11,
"points_per_game": "8.4",
"ep_this": "6.5",
"ep_next": "6.3",
"special": false,
"minutes": 2905,
"goals_scored": 32,
"assists": 12,
"clean_sheets": 15,
"goals_conceded": 29,
"own_goals": 0,
"penalties_saved": 0,
"penalties_missed": 1,
"yellow_cards": 1,
"red_cards": 0,
"saves": 0,
"bonus": 26,
"bps": 881,
"influence": "1496.2",
"creativity": "942.5",
"threat": "2109.0",
"ict_index": "454.4",
"ea_index": 0,
"element_type": 3,
"team": 10
}
It would be tedious to create tables with so many columns by hand. Fortunately, the data was well structured—the objects were all flat or mostly flat and attribute values only came in 4 different types (integer, real, string and boolean)—so the table creation could be automated.
Here's an example function to generate a CREATE TABLE query based on the attributes of an object:
def generate_create_table_query(example, table_name):
columns = []
for k, v in example.items():
column_name = k
if isinstance(v, int):
type_name = 'integer'
elif isinstance(v, bool):
type_name = 'boolean'
elif isinstance(v, str):
try:
float(v)
type_name = 'real'
except ValueError:
type_name = 'text'
else:
raise ValueError(f'value for key "{k}" had unexpected type: "{v}"')
columns.append(f' {column_name} {type_name}')
query = f'CREATE TABLE {table_name} (\n'
query += ',\n'.join(columns)
query += '\n)'
return query
This generates the following query when run on the sample player object from the start of the section:
CREATE TABLE players (
id integer,
photo text,
web_name text,
team_code integer,
status text,
code integer,
first_name text,
second_name text,
squad_number integer,
news text,
now_cost integer,
news_added text,
chance_of_playing_this_round integer,
chance_of_playing_next_round integer,
value_form real,
value_season real,
cost_change_start integer,
cost_change_event integer,
cost_change_start_fall integer,
cost_change_event_fall integer,
in_dreamteam integer,
dreamteam_count integer,
selected_by_percent real,
form real,
transfers_out integer,
transfers_in integer,
transfers_out_event integer,
transfers_in_event integer,
loans_in integer,
loans_out integer,
loaned_in integer,
loaned_out integer,
total_points integer,
event_points integer,
points_per_game real,
ep_this real,
ep_next real,
special integer,
minutes integer,
goals_scored integer,
assists integer,
clean_sheets integer,
goals_conceded integer,
own_goals integer,
penalties_saved integer,
penalties_missed integer,
yellow_cards integer,
red_cards integer,
saves integer,
bonus integer,
bps integer,
influence real,
creativity real,
threat real,
ict_index real,
ea_index integer,
element_type integer,
team integer
)
It would be similarly tedious to write out all the necessary INSERT statements with varying amounts of placeholders—these could be generated automatically too:
def insert(conn, table_name, item):
num_columns = len(item)
query = f'INSERT INTO {table_name} VALUES ({", ".join("?" * num_columns)})'
values = item.values()
c = conn.cursor()
c.execute(query, values)
Additional notes
I used modified versions of the above functions to exclude certain attributes containing redundant denormalised data in the form of nested objects which could not be easily mapped to columns, and also to specify additional constraints for columns such as primary and foreign key constraints where applicable.
Later on, I also realised that certain attributes in the data are quite volatile—specifically the value related attributes on player objects: value_form, form and ep_this—when I was trying to reproduce my dataset and the generated SQLite database was slightly different, discovering the useful sqldiff.exe tool in the process. Perhaps these attributes should be excluded from the dataset as well in future?