When trying to extract data from websites, it's not always necessary to immediately turn to scraping techniques. Many contemporary websites are not fully server rendered and instead dynamically fetch data from backend services. By identifying these backend services and making requests to them directly, it's often possible to get more data than is actually displayed on the website, and in a more machine-readable form.
In this post, we'll go through an example application of such a technique.
Scenario
Let's imagine we want to get a list of data centres and their locations in Australia from the following website:

The search page only shows 8 results at a time, and we're told to “Join or log in to see 250 more results”.
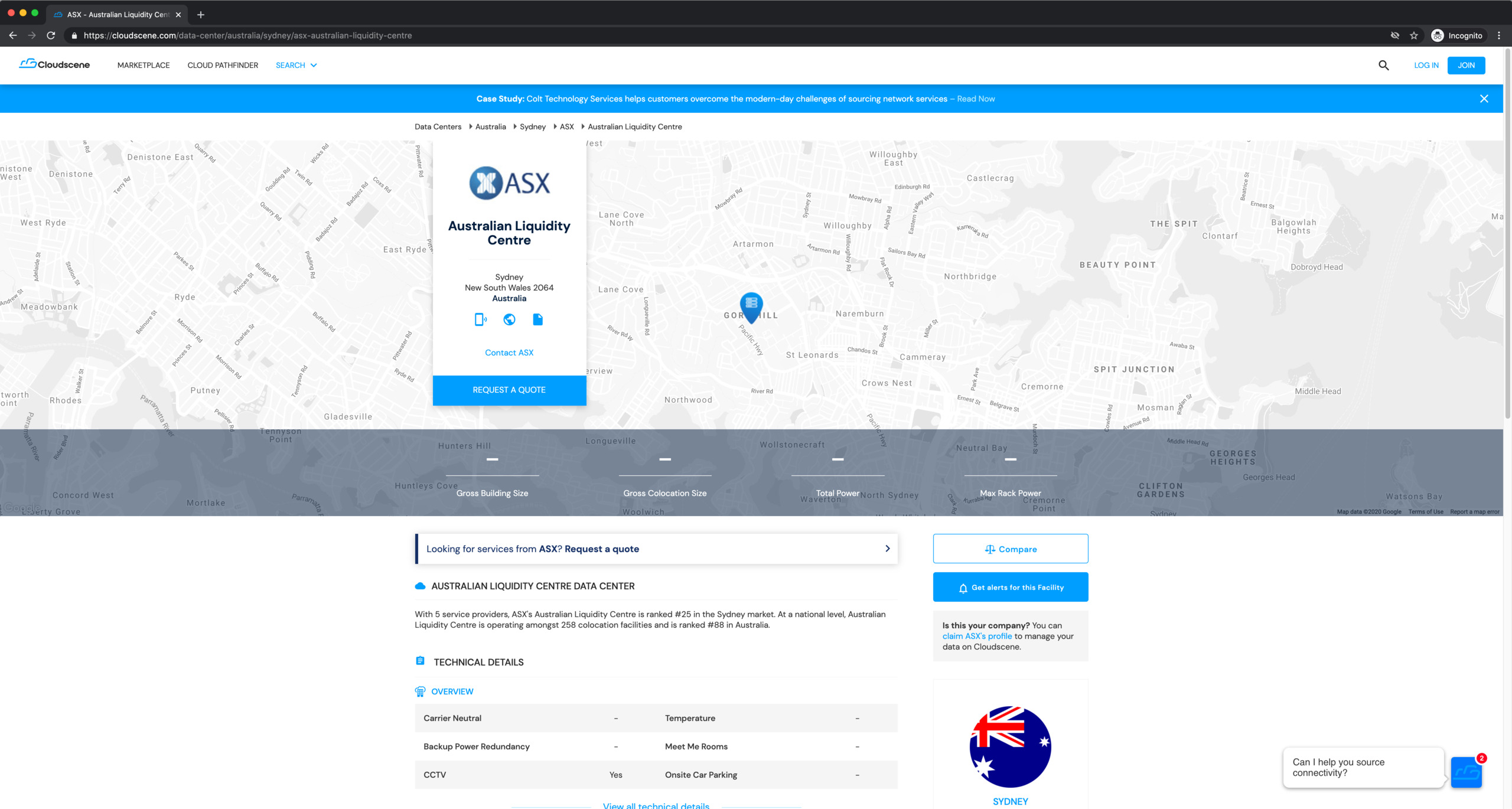
We have to click into each individual result to see its location on a map, but there's no copyable address or coordinate string:
Methodology
Check network requests
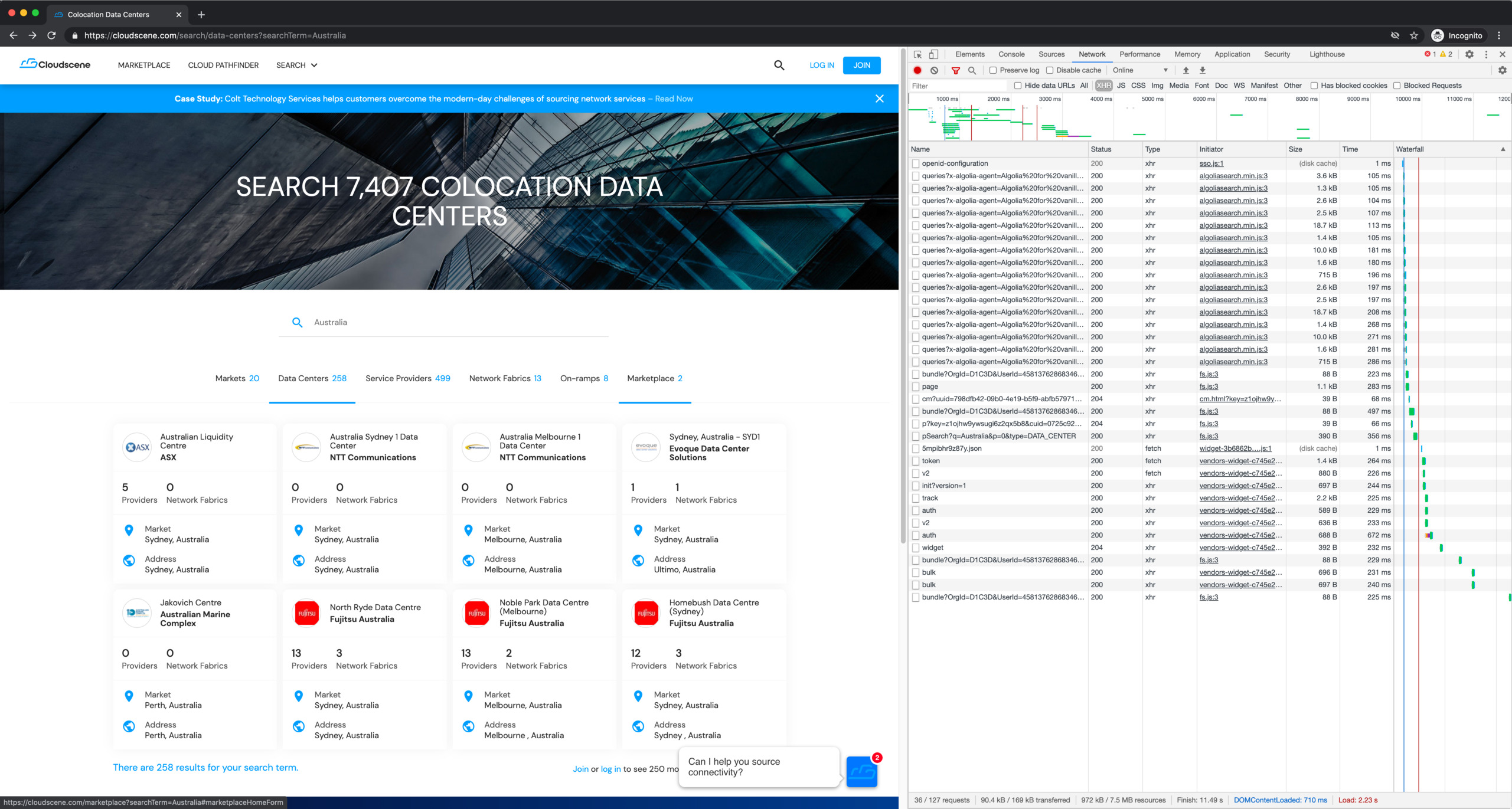
The first thing to do is to determine if the data on the page is static (server rendered) or dynamically requested by the page. We can do this with the Network tab in the browser devtools. I usually show only the XHR requests because those are the interesting ones:
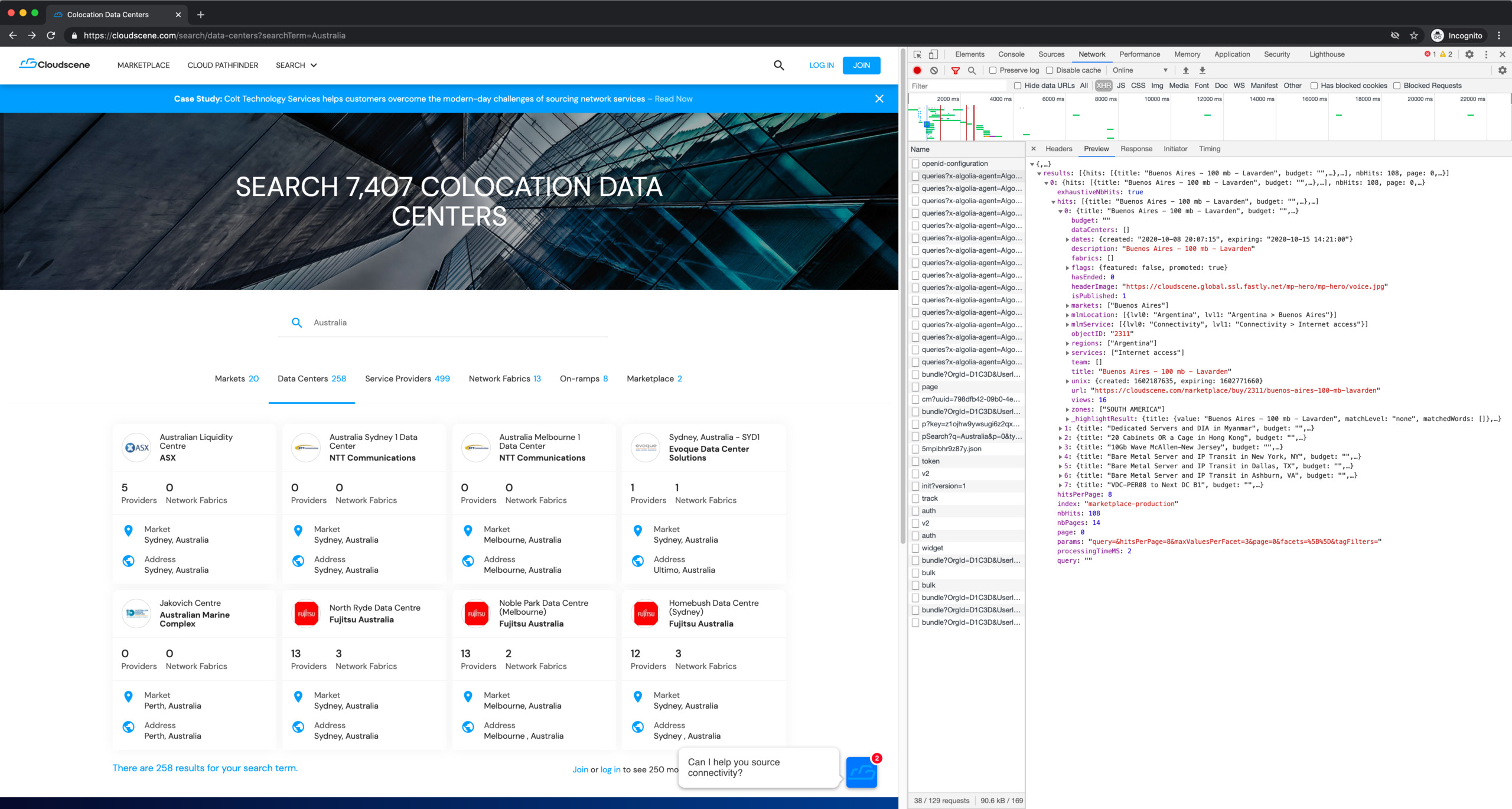
Quickly scan through the response previews, and we can immediately see some juicy data:
We can search for some of the data we see on screen, and bingo:
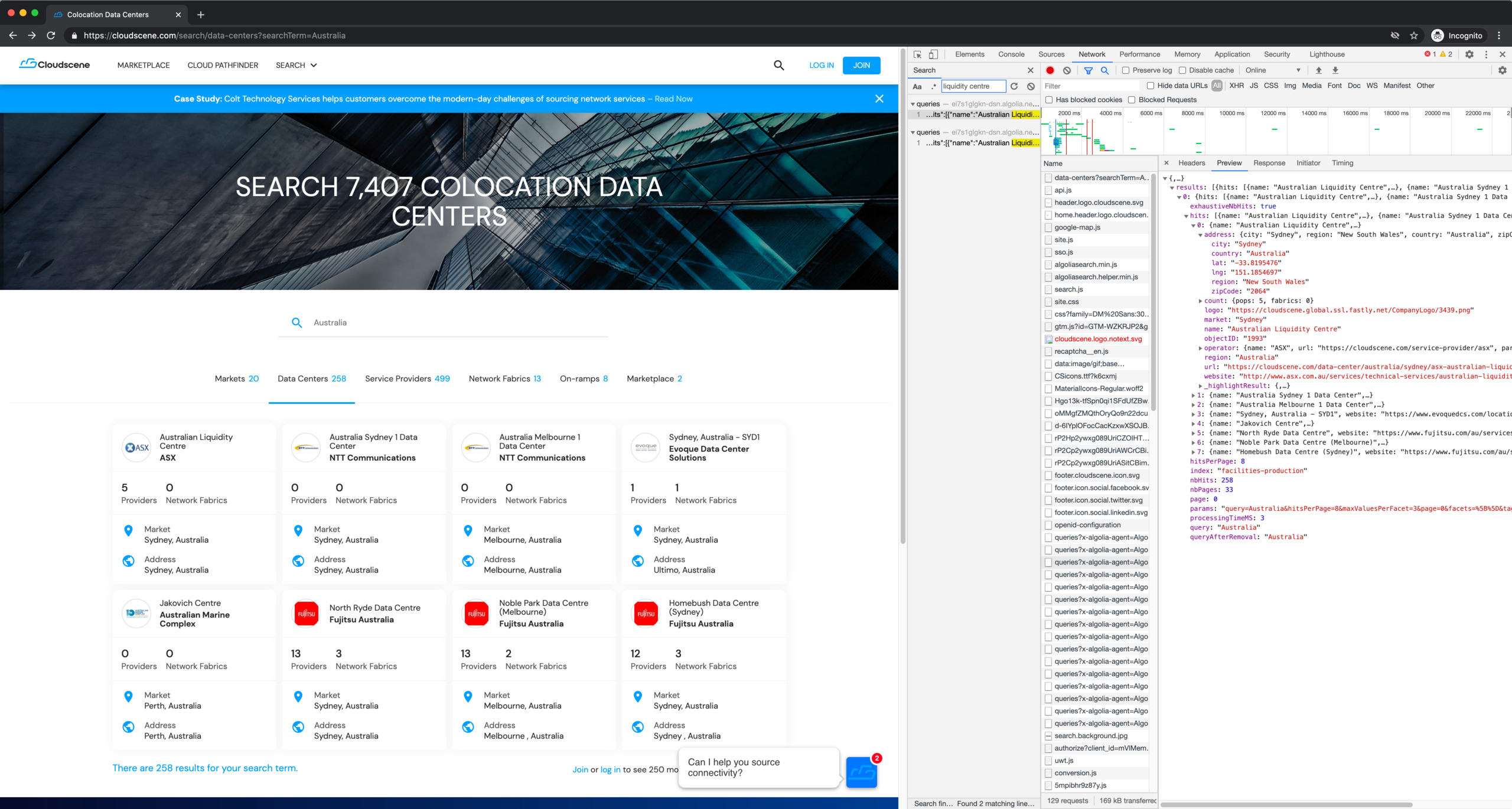
Inspecting the response data more closely, we can see it contains all the data we want, and more:
{
"name": "Australian Liquidity Centre",
"website": "http://www.asx.com.au/services/technical-services/australian-liquidity-centre.htm",
"market": "Sydney",
"region": "Australia",
"url": "https://cloudscene.com/data-center/australia/sydney/asx-australian-liquidity-centre",
"logo": "https://cloudscene.global.ssl.fastly.net/CompanyLogo/3439.png",
"count": {
"pops": 5,
"fabrics": 0
},
"operator": {
"name": "ASX",
"url": "https://cloudscene.com/service-provider/asx",
"parent": []
},
"address": {
"city": "Sydney",
"region": "New South Wales",
"country": "Australia",
"zipCode": "2064",
"lat": "-33.8195476",
"lng": "151.1854697"
},
"objectID": "1993",
"_highlightResult": {
"name": {
"value": "<em>Australian</em> Liquidity Centre",
"matchLevel": "full",
"fullyHighlighted": false,
"matchedWords": [
"australia"
]
},
"website": {
"value": "http://www.asx.com.au/services/technical-services/<em>australian</em>-liquidity-centre.htm",
"matchLevel": "full",
"fullyHighlighted": false,
"matchedWords": [
"australia"
]
},
"market": {
"value": "Sydney",
"matchLevel": "none",
"matchedWords": []
},
"region": {
"value": "<em>Australia</em>",
"matchLevel": "full",
"fullyHighlighted": true,
"matchedWords": [
"australia"
]
},
"zones": [
{
"value": "OCEANIA",
"matchLevel": "none",
"matchedWords": []
}
],
"operator": {
"name": {
"value": "ASX",
"matchLevel": "none",
"matchedWords": []
}
},
"address": {
"city": {
"value": "Sydney",
"matchLevel": "none",
"matchedWords": []
},
"region": {
"value": "New South Wales",
"matchLevel": "none",
"matchedWords": []
},
"country": {
"value": "<em>Australia</em>",
"matchLevel": "full",
"fullyHighlighted": true,
"matchedWords": [
"australia"
]
},
"zipCode": {
"value": "2064",
"matchLevel": "none",
"matchedWords": []
}
}
}
}
We can copy the data for the 8 results displayed on screen from the response. But can we get the other 250 results?
Let's switch to the “Headers” tab and take a closer look:
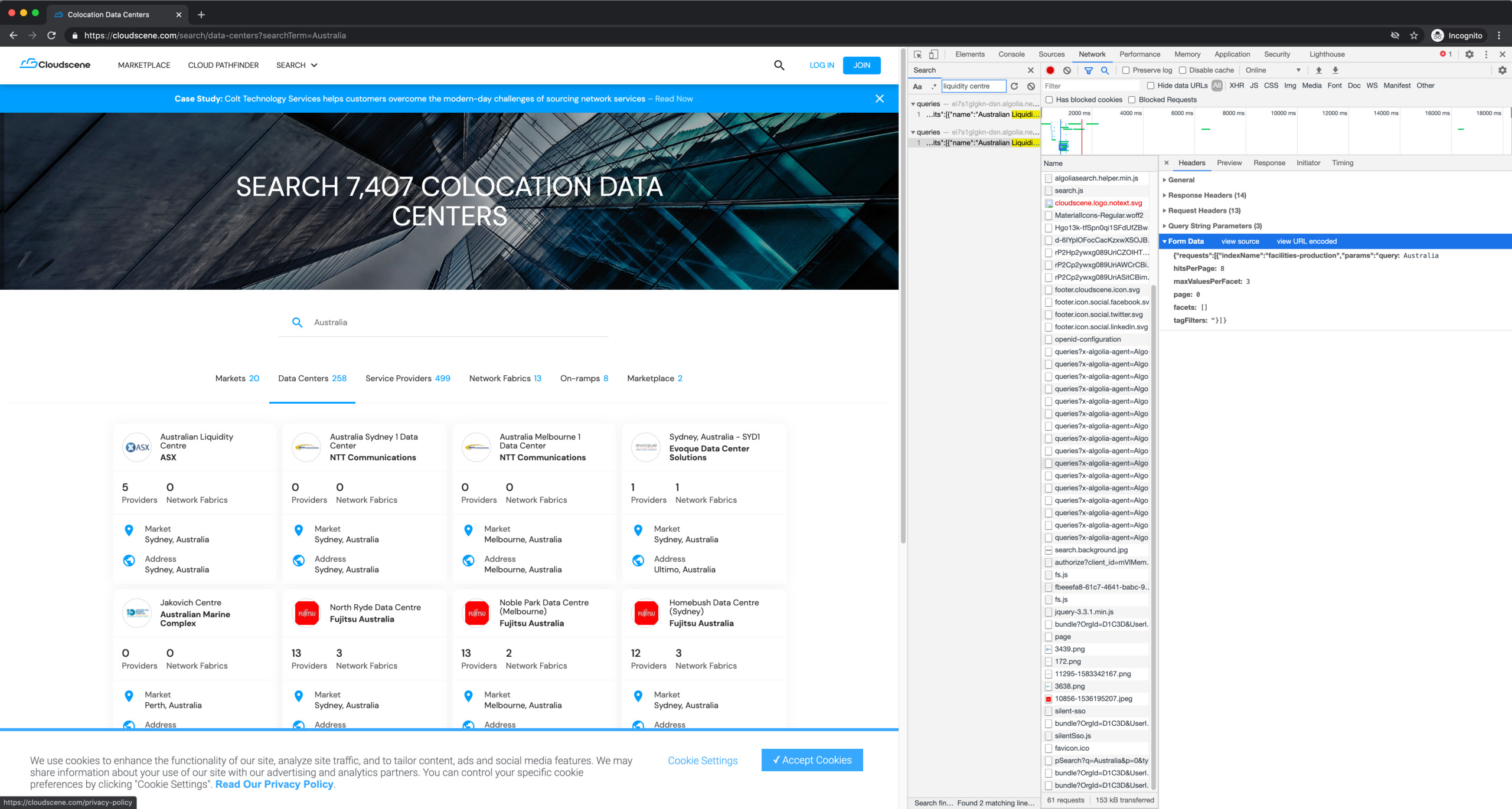
In the “Form Data” section, we can see a promising parameter: hitsPerPage: 8.
What if we made it larger? Could we request all 258 results at once?
To do this, we can copy the original request as a curl command to send it on
our own instead of through the browser:

We can freely modify and run the copied curl command, saving the results to a
file:
$ curl 'https://xxx-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20vanilla%20JavaScript%203.17.0&x-algolia-application-id=xxx&x-algolia-api-key=xxx' \
-H 'Connection: keep-alive' \
-H 'accept: application/json' \
-H 'User-Agent: xxx' \
-H 'content-type: application/x-www-form-urlencoded' \
-H 'Origin: https://cloudscene.com' \
-H 'Sec-Fetch-Site: cross-site' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Referer: https://cloudscene.com/' \
-H 'Accept-Language: en-GB,en;q=0.9' \
--data-raw '{"requests":[{"indexName":"facilities-production","params":"query=Australia&hitsPerPage=258&maxValuesPerFacet=3&page=0&facets=%5B%5D&tagFilters="}]}' \
--compressed > results.json
I compared the result with hitsPerPage: 8 and hitsPerPage: 258, and it was a
pleasant surprise that the hitsPerPage parameter actually works as expected:
$ jq '.results[].hits[]' -c < results1.json | wc -l
8
$ jq '.results[].hits[]' -c < results2.json | wc -l
258
At this point, we have a JSON document containing all the data we need, with the
following structure, where the ... represents more results:
{
"results": [
{
"hits": [
{
"name": "Australian Liquidity Centre",
"website": "http://www.asx.com.au/services/technical-services/australian-liquidity-centre.htm",
"market": "Sydney",
"region": "Australia",
"url": "https://cloudscene.com/data-center/australia/sydney/asx-australian-liquidity-centre",
"logo": "https://cloudscene.global.ssl.fastly.net/CompanyLogo/3439.png",
"count": {
"pops": 5,
"fabrics": 0
},
"operator": {
"name": "ASX",
"url": "https://cloudscene.com/service-provider/asx",
"parent": []
},
"address": {
"city": "Sydney",
"region": "New South Wales",
"country": "Australia",
"zipCode": "2064",
"lat": "-33.8195476",
"lng": "151.1854697"
},
"objectID": "1993",
"_highlightResult": {
"name": {
"value": "<em>Australian</em> Liquidity Centre",
"matchLevel": "full",
"fullyHighlighted": false,
"matchedWords": [
"australia"
]
},
"website": {
"value": "http://www.asx.com.au/services/technical-services/<em>australian</em>-liquidity-centre.htm",
"matchLevel": "full",
"fullyHighlighted": false,
"matchedWords": [
"australia"
]
},
"market": {
"value": "Sydney",
"matchLevel": "none",
"matchedWords": []
},
"region": {
"value": "<em>Australia</em>",
"matchLevel": "full",
"fullyHighlighted": true,
"matchedWords": [
"australia"
]
},
"zones": [
{
"value": "OCEANIA",
"matchLevel": "none",
"matchedWords": []
}
],
"operator": {
"name": {
"value": "ASX",
"matchLevel": "none",
"matchedWords": []
}
},
"address": {
"city": {
"value": "Sydney",
"matchLevel": "none",
"matchedWords": []
},
"region": {
"value": "New South Wales",
"matchLevel": "none",
"matchedWords": []
},
"country": {
"value": "<em>Australia</em>",
"matchLevel": "full",
"fullyHighlighted": true,
"matchedWords": [
"australia"
]
},
"zipCode": {
"value": "2064",
"matchLevel": "none",
"matchedWords": []
}
}
}
},
...
],
"nbHits": 258,
"page": 0,
"nbPages": 33,
"hitsPerPage": 8,
"exhaustiveNbHits": true,
"query": "Australia",
"queryAfterRemoval": "Australia",
"params": "query=Australia&hitsPerPage=8&maxValuesPerFacet=3&page=0&facets=%5B%5D&tagFilters=",
"index": "facilities-production",
"processingTimeMS": 2
}
]
}
However, some users may be more comfortable working with CSV files. We can use
the jq command to extract only the fields we're interested in from the JSON
and output it in CSV format:
$ jq '.results[].hits[] | [.name, .address.city, .address.region, .address.country, .address.zipCode, .address.lat, .address.lng] | @csv' -r < results.json > results.csv
$ head results.csv
"Australian Liquidity Centre","Sydney","New South Wales","Australia","2064","-33.8195476","151.1854697"
"Australia Sydney 1 Data Center","Sydney","New South Wales","Australia","2007","-33.8795793","151.18570679999993"
"Australia Melbourne 1 Data Center","Melbourne","Victoria","Australia","3207","-37.834848","144.93129499999998"
"Sydney, Australia - SYD1","Ultimo","New South Wales","Australia","2007","-33.8756413","151.1975863"
"Jakovich Centre","Perth","Western Australia","Australia","6004","-31.96239199999999","115.876121"
"North Ryde Data Centre","Sydney","New South Wales","Australia","2113","-33.78669","151.131855"
"Noble Park Data Centre (Melbourne)","Melbourne ","Victoria","Australia","3174","-38.15751900000001","145.124178"
"Homebush Data Centre (Sydney)","Sydney ","New South Wales","Australia","2127","-33.84984","151.07162"
"Eight Mile Plains Data Centre","Brisbane","Queensland","Australia","4113","-27.5820364","153.0977931"
"Malaga Data Centre","Perth","Western Australia","Australia","6090","-31.8595587","115.8955513"
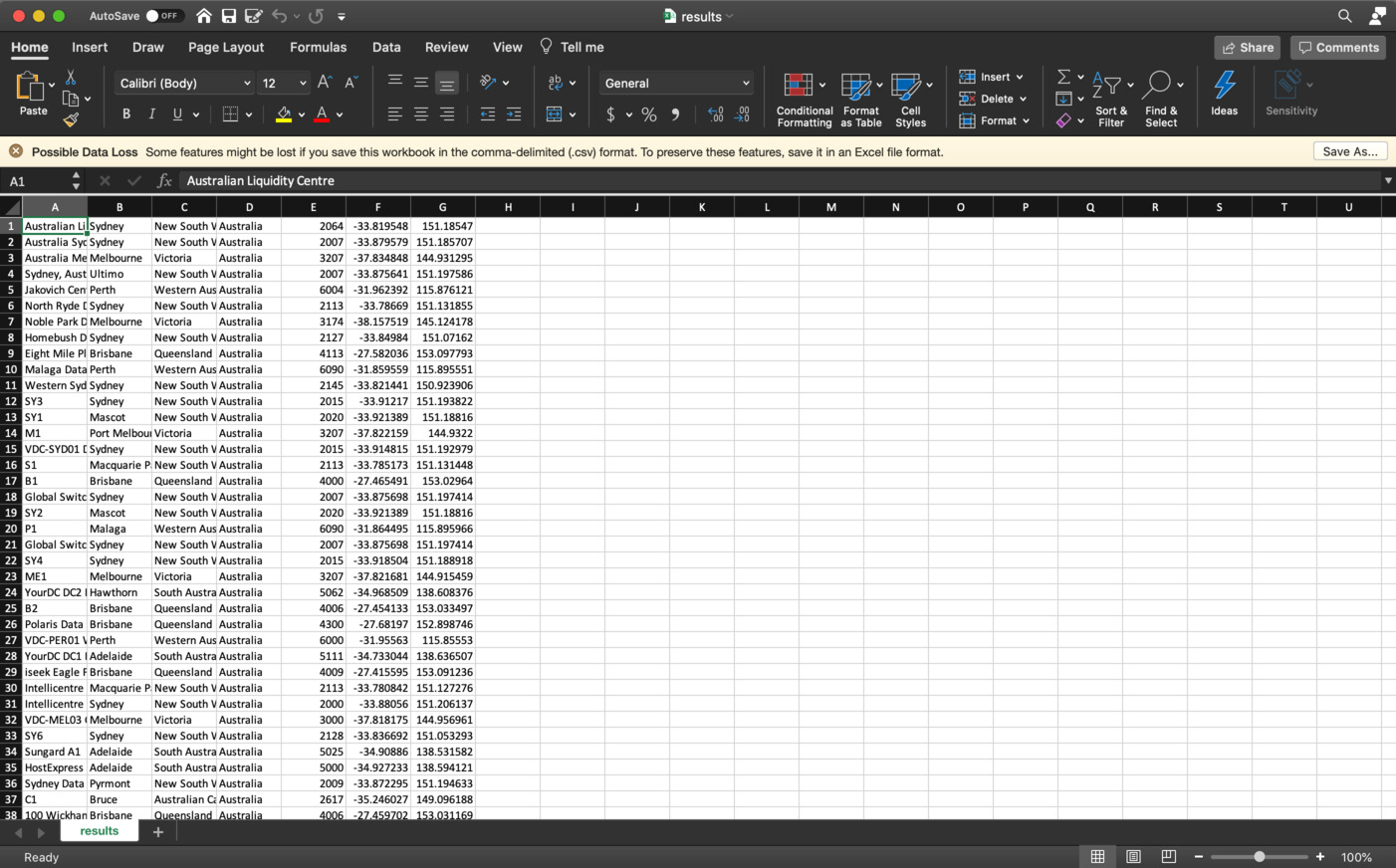
The resulting CSV file can be processed in a spreadsheet:
Appendix
While writing this post, I ended up exceeding my guest search limit:
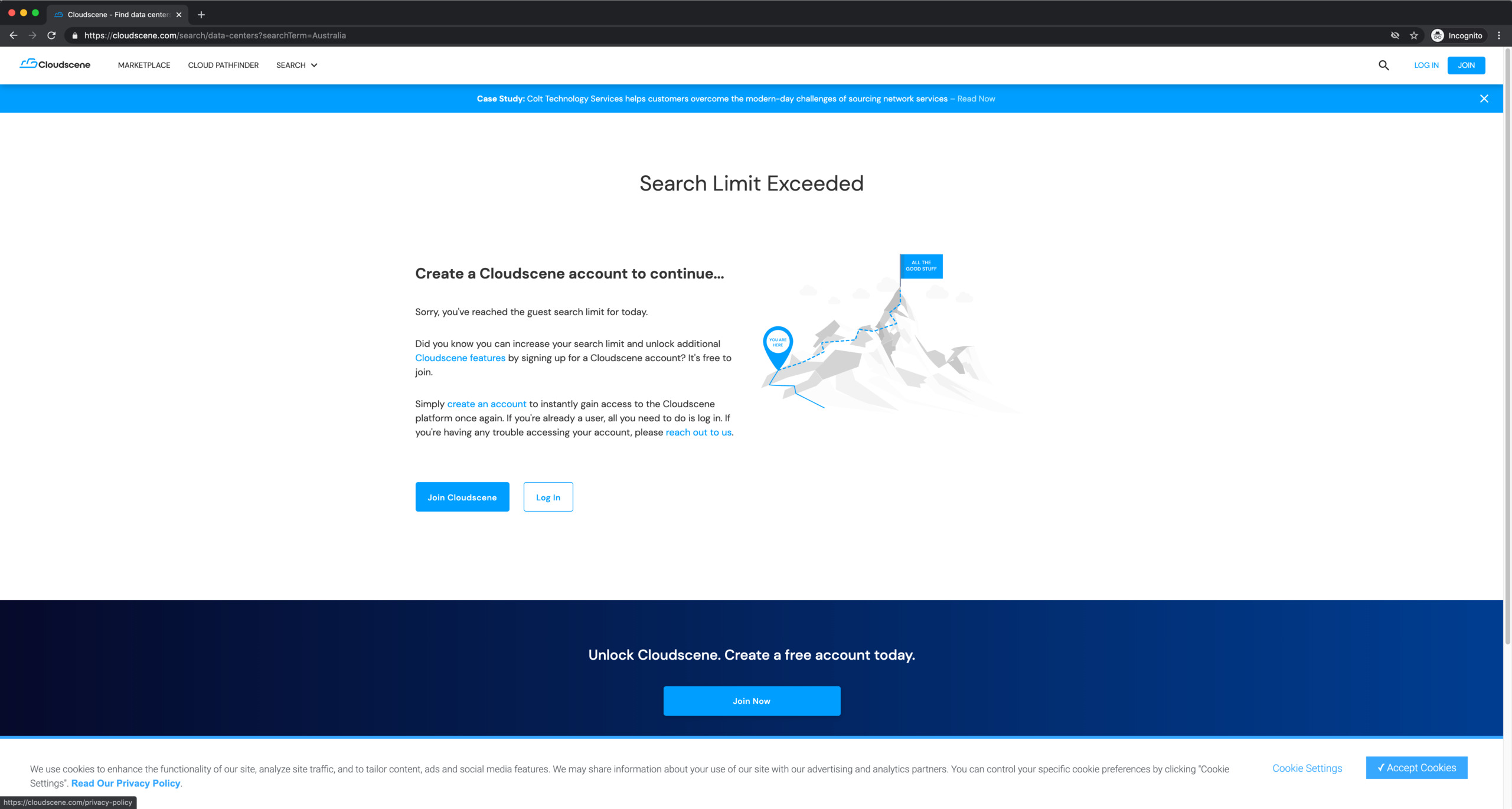
Interestingly, the curl command I copied earlier still works, despite the
various high entropy keys it contained.